
记录下当时解的两道pwn,defile和2077
defile
这题初赛就有了,而且看了下决赛题目的代码,没有啥变化,只是加了计分的规则,原先是从输入流读取的shellcode,现在变成从文件读取,决赛这题是koh,要求我们交一个文件,里面包含了我们的shellcode,下面就对这道题的代码进行分析,解题见:https://zhangyidong.top/2020/11/04/Xnuca2020%E7%BA%BF%E4%B8%8A%E8%B5%9B/
没有进行很好的优化,如果有兴趣的话可以继续优化下这个shellcode
代码分析
1 |
|
题目是怎么算分数的:
1 | int getanswer(char *path, char *shared){ |
这题计算分数就是很简单,你的shellcode越短,分数就越高,前提是你的shellcode能完成那128轮的循环
2077
这题比较有意思,出题人自己写了一个compiler,读取->解析->运行 我们的代码
代码分析
先看下目录树:
1 | . |
用ida打开压缩包里的pwn程序,能定位到main函数应该是compiler的main.c,程序一开始会叫我们输入代码的size,接着读取我们输入的代码,然后解析执行就结束了,所以我们要找到编译器里对代码进行解析的漏洞,比如没有对数组的下标进行check,或者类型转换检查不严格之类的漏洞。
漏洞
写在最前面,编译器要求调用函数前我们一定要声明该函数的原型,用afl++来插桩,fuzz失败了。。所以下面漏洞都是直接读源码找的
readfile
比赛的时候没过多久就被人打了,tr3e学长看了下源码,发现有后门函数,这是编译器内置的函数:
1 | // pvm/native.c |
可以看见有一个readfile的函数还有print,这个readfile是可以打开文件的:
1 | static PVM_Value |
可以看到有一个check,但是这个check可以用lnk函数来绕过:
1 | static PVM_Value |
lnk函数也有对包含flag字样的路径进行check,但是细看一下,它检查的是dst字符串中是否包含flag字样,而不是src字符串里是否包含flag,所以着检查没啥用,第一版exp:
1 | from pwn import * |
本来是lnk到当前目录下的,但是当前目录没有写权限,最后发现/tmp目录有写权限,所以就lnk到/tmp目录了
个人觉得这种题目,编译器解析的语言,我们可以类比c语言,java,java script这些语言定义变量,定义函数,调用函数的语法来试编译器解析的语言的语法,当然源码中也给出了语法(compiler/proto.y):
1 | %{ |
这文件是应该是yacc lex解析的文件,当时只是粗略的看了下,大部分还都是瞎试出来的,:P
proto.l文件给的内容也很详细,是具体解析词法的正则表达式形式:
1 | %{ |
patch漏洞
说来惭愧,只修了这个洞
就是把pvm/native.c里的nv_lnk_proc函数:
1 | if(wcsstr(dst, L"flag") != NULL){ |
改成:
1 | if(wcsstr(src, L"flag") != NULL){ |
检查源文件的路径是否包含flag字样来杜绝flag文件被lnk到/tmp目录下
unhex
poc:
1 | string unhex(string s); |
这个可以堆溢出,但是没想到怎么利用上,最后没写出exp,漏洞对应源代码中的:
1 | // pvm/native.c |
喜闻乐见的格式化字符串漏洞,poc:
1 | string print(string s); |
漏洞点的源代码在:
1 | // pvm/native.c |
share/wchar.c
1 | int |
但是由于程序没有读取我们后续输入的操作,所以这个漏洞也没利用成功,有点可惜
type confusion
类型混淆
由tr3e学长发现,orz
poc:
1 | string hex(int x); |
因为类型混淆了,所以导致了越界读写,原本int是4字节的,而double是8字节的,可操作的空间足足大了两倍,为后续利用起到了至关重要的作用
原因应该是:
1 | // compiler/generate.c |
generate_assign_expression没有对数组的赋值进行check,还有一个就是编译器允许int转换成double,double可以转换成一个包含两个元素的int数组:
1 | // pvm/native.c 没错还是这个文件,感觉漏洞都是出现在这几个内置的函数上 |
可以看到都没有进行检查,所以强制类型转换的时候导致了类型混淆
exp:
1 | from pwn import * |
这是我在Ubuntu18.04下利用的脚本,其中offset和数组的下标要根据字节的情况调整,这里说一下,数组的下标5182463是libc got表里的一个函数,下标5183765是__free_hook的位置,但是有个很坑的点,本地和远程的地址分布不一样,还好以前踩过,比赛的时候顺利解决。
解决本地和远程地址分布不一样
本地:
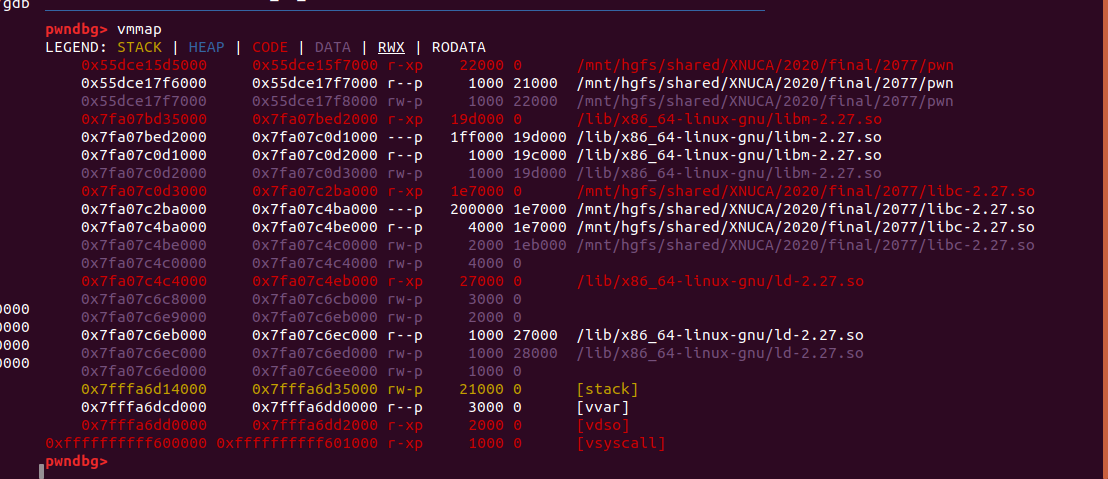 ]
]
远程:
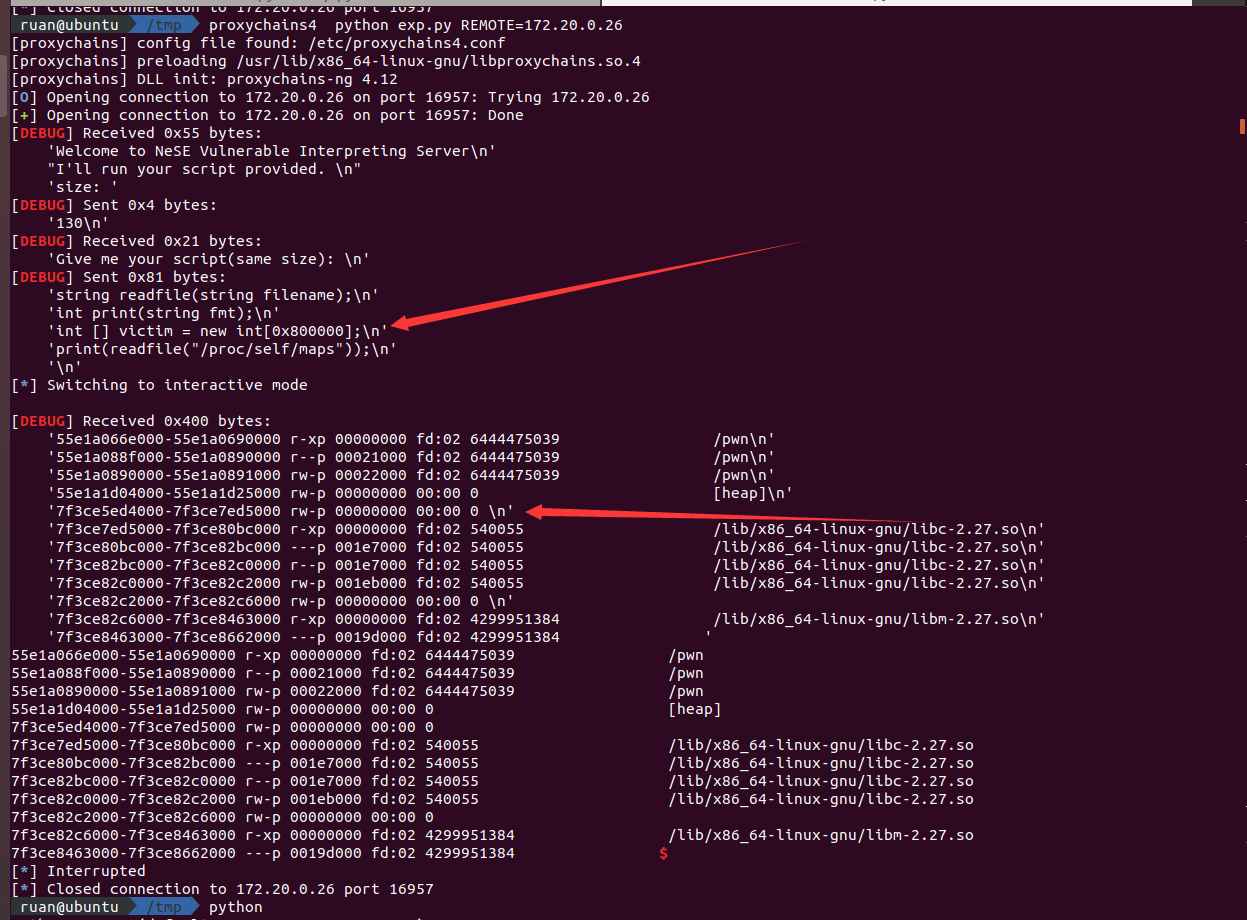 ]
]
怎么读的呢,直接读/proc/self/maps,算好偏移,再打过去的时候成功。
读/proc/self/maps确定远程地址映射情况的代码:
1 | string readfile(string filename); |
修改后的exp:
1 | offset = 4709653 |
然后就是说一下为什么要申请一个0x800000大小的int数组,这是为了让这个数组mmap在libc上方,和libc的偏移固定,这样我们类型混淆后可以越界读写libc的数据来劫持程序流程,exp用的方法是改了__free_hook为one_gadget来getshell的
踩坑
最最后说一下那一堆0.00000是在干嘛,程序只有两种基本类型,int和double,和JavaScript很像,所以我们输入的int会被转为double,这点很蛋疼,因为这样直接加偏移的话被转换成double之后会出现误差,当时一度卡在这里,最后通过阅读源码:
1 | // compiler/proto.l |
我们可以看到用的是sscanf的%lf来处理浮点数的,然后再看那个正则:
1 | <INITIAL>[0-9]+\.[0-9]+ |
代表程序只认0.1123这种类型的浮点数,连带个负号都不行,所以我们上面exp里找的libc got表里的函数的地址要比one_gadget的地址低,这样才能用相加的办法来得到one_gadget
根据这个转换的结果:
1 | >>> import struct |
我们得把3.4673e-319改成0.00000....00034673这样的形式。
总结
这题出的真的棒